1.For PCA, in order to find U and W we need to find a solution to the following objective function:

How can we simplify the equation above such that we transform the problem into a trace maximisation problem? Show the intermediate steps and the new objective function.
Solution:



Now we turn the objective into a trace maximisation problem:


If we define 

2.With a mean-centered data matrix X, a key component of PCA is the spectral decomposition of a matrix M defined as M= VDVT where:
M ∈Rd,d
V is a matrix whose columns 
D is the diagonal matrix with 


Assume that obtaining the square matrix M is computationally expensive. Can you
suggest an alternative method to obtain the eigenvectors of M?
Solution:
Consider 

Suppose v is an eigenvector of K: 

Multiplying the equation by 

But, using the definition of 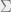

Hence 

Therefore, we can calculate the PCA solution by calculating the eigenvalues of K rather than
3.In PCA, W is the compression matrix and U is the recovering matrix. The corresponding objective of finding W and U is phrased as:

Prove the lemma: Let (U,W) be a solution to Objective(1). Then the columns of U are orthonormal (that is, 


Solution:
Choose any U and W and consider the mapping

The range of this mapping, 

Let 

Each vector in R can be written as 

For every 

This difference is minimised for 
Therefore, for each 

This holds for all 


As this holds for any U,W, the proof is complete.
4.Let 



Solution:
Choose a matrix 



and therefore

Note that 

Define 



It follows that
![trace(U^T\Sigma U)\leq max_{\beta\in [0,1]^d:\Vert\beta\Vert_1\leq r}\sum^d_{j=1}D_{j,j}\beta_j=\sum^r_{j=1}D_{j,j}](https://s0.wp.com/latex.php?latex=trace%28U%5ET%5CSigma+U%29%5Cleq+max_%7B%5Cbeta%5Cin+%5B0%2C1%5D%5Ed%3A%5CVert%5Cbeta%5CVert_1%5Cleq+r%7D%5Csum%5Ed_%7Bj%3D1%7DD_%7Bj%2Cj%7D%5Cbeta_j%3D%5Csum%5Er_%7Bj%3D1%7DD_%7Bj%2Cj%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Therefore for every matrix 

But if we set U to the matrix with the r leading eigenvectors of 
5.The variance captured by the first r eigenvectors of 

Solution:
The variance in a dataset X is defined as




The variance in a projected dataset WX, with ![W=[\pmb{v}_1,...,\pmb{v}_r]^T](https://s0.wp.com/latex.php?latex=W%3D%5B%5Cpmb%7Bv%7D_1%2C...%2C%5Cpmb%7Bv%7D_r%5D%5ET+&bg=eeeeee&fg=666666&s=0&c=20201002)



(Based on 4, we know that the eigenvectors are orthonormal.)


 for forward edges and
for forward edges and  for backward edges.
for backward edges.

 and
and  are both forward edges, then
are both forward edges, then  if one of the following holds:
if one of the following holds:
 and
and 
 and
and 

 and
and 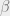

 if and only if either of the following is true
if and only if either of the following is true and
and 
 and
and 


 and nonzero eigenvectors v in Hilbert space satisfying:
and nonzero eigenvectors v in Hilbert space satisfying: 
 lie in the span of
lie in the span of  , due to the fact that
, due to the fact that (
( is a inner product between two vectors, it is a scalar. So we can reorder it to the front. )
is a inner product between two vectors, it is a scalar. So we can reorder it to the front. ) and multiply it on both side. We can get
and multiply it on both side. We can get 

 (
( )
) (43)
(43) (
(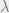 is a constant)
is a constant) (
( is a constant)
is a constant)
 ; (44)
; (44) ; (45)
; (45) . (46)
. (46)
![\sum^n_{k=1}K_{jk}K_{ki}=[K\cdot K]_{ji}=[K^2]_{ij}](https://s0.wp.com/latex.php?latex=%5Csum%5En_%7Bk%3D1%7DK_%7Bjk%7DK_%7Bki%7D%3D%5BK%5Ccdot+K%5D_%7Bji%7D%3D%5BK%5E2%5D_%7Bij%7D&bg=eeeeee&fg=666666&s=0&c=20201002) (This is the definition of matrix multiplication: the jth row of K multiply with the ithcolumn of K is the ij entry of the result matrix.)
(This is the definition of matrix multiplication: the jth row of K multiply with the ithcolumn of K is the ij entry of the result matrix.) (47)
(47) denotes the column vector with entries
denotes the column vector with entries 

 from the left.
from the left. to have unit length, that is
to have unit length, that is  for all k=1,…,r.
for all k=1,…,r.



 , the
, the  have unit form.
have unit form. to enforce that their norm is
to enforce that their norm is  .
.